近期一直都有关注数据的采集方面的开发,之前也用Python(urllib+BeautifulSoup)写过“爬虫”但是效果不是很好,表现在内存占用过高和做出来的东西不够通用,很多周边的东西(图片下载、缩略图等)都需要自己来实现。
趁着近期在公司内部弄到了一台新的CentOS服务器的机会就索性使用Scrapy把前段时间写的空气质量采集的程序改写下,同时把SQLServer换成MySQL,顺便熟悉一下这块的知识。
![]()
开发环境准备
CentOS 6.5自带的是Python 2.6.6,使用Scrapy需要的Python版本是2.7,所以需要将Python的环境先升级。
1.准备安装Python的环境
(1)安装devtoolset
yum groupinstall "Development tools"
(2)安装编译Python需要的包
yum install zlib-devel
yum install bzip2-devel
yum install openssl-devel
yum install ncurses-devel
yum install sqlite-devel
(3)安装MySQL驱动
yum install mysql-devel
2.Python开发环境安装
(1)下载Python2.7版本
wget --no-check-certificate https://www.python.org/ftp/python/2.7.11/Python-2.7.11.tar.xz
(2)解压
tar -jxvf Python-2.7.11.tar.xz
cd Python-2.7.11
(3)安装和编译
./configure --prefix=/usr/local
make && make altinstall
(4)将python命令指向最新的
ln -s /usr/local/bin/python2.7 /usr/bin/python
(5)检查Python的版本
python --version
3.安装pip
(1)下载pip安装脚本
wget --no-check-certificate https://bootstrap.pypa.io/get-pip.py
(2)执行安装脚本
python get-pip.py
(3)使用pip镜像
在安装某些包的时候可能会出现网络方面的问题,推荐使用国内的镜像方式进行安装,有如下镜像地址可供选择:
http://mirrors.sohu.com/python/ 搜狐
http://pypi.douban.com/ 豆瓣
http://pypi.hustunique.com/ 华中理工大学
http://pypi.sdutlinux.org/ 山东理工大学
http://pypi.mirrors.ustc.edu.cn/ 中国科学技术大学
安装的时候使用如下的格式:
pip install --index 镜像地址 包名
4.安装scrapy
(1)安装scrapy组件
pip install scrapy
(2)安装MySQLdb的组件:
pip install MySQL-python
Scrapy快速入门
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
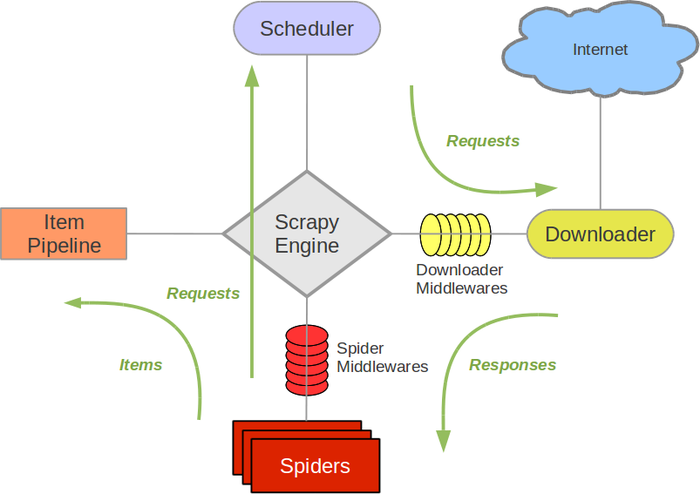
1.组件介绍
(1)核心引擎(Scrapy Engine):
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
(2)调度器(Scheduler):
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
(3)下载器(Downloader):
下载器负责获取页面数据并提供给引擎,而后提供给spider。
(4)爬虫模块(Spiders):
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
(5)Item Pipeline:
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
(6)下载器中间件(Downloader middlewares):
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
(7)Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
2.数据流
Scrapy中的数据流由执行引擎控制,其过程如下:
(1)引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
(2)引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
(3)引擎向调度器请求下一个要爬取的URL。
(4)调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
(5)一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
(6)引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
(7)Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
(8)引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(9)(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
使用示例
1.创建项目
scrapy startproject tutorial
2.创建Spider
scrapy genspider pm25
3.编写Items
import scrapy
class Pm25CityItem(scrapy.Item):
city_name = scrapy.Field() #城市的名称
home_link = scrapy.Field() #对应数据的链接地址
city_pinyin = scrapy.Field() #城市的拼音
4.完善Spider
import scrapy
from tutorial.items import Pm25CityItem
class Pm25Spider(scrapy.Spider):
name = "pm25"
allowed_domains = ["pm25.in"]
start_urls = [
'http://www.pm25.in',
]
def parse(self, response):
sel = scrapy.Selector(response)
citys = sel.xpath("//div[@class='all']/div[@class='bottom']/ul[@class='unstyled']/div[2]/li")
city_items = []
for city in citys:
city_item = Pm25CityItem()
href = ''.join(city.xpath('a/@href').extract()).strip()
city_item['city_name'] = ''.join(city.xpath('a/text()').extract()).strip().encode("UTF-8")
city_item['home_link'] = 'http://www.pm25.in' + href
city_item['city_pinyin'] = href.split('/')[1]
city_items.append(city_item)
return city_items
5.配置settings.py文件
(1)配置MySQL数据源
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'test' #数据库名字
MYSQL_USER = 'root' #数据库账号
MYSQL_PASSWD = '123456' #数据库密码
MYSQL_PORT = 3306 #数据库端口
(2)配置MySQL存储的Pipeline
ITEM_PIPELINES = {
'tutorial.pipelines.MySQLStoreDataPipeline': 300, #保存到数据库
}
6.数据的存储
from scrapy import log
from twisted.enterprise import adbapi
import datetime, uuid
import MySQLdb
import MySQLdb.cursors
class MySQLStoreDataPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbargs = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode= True,)
dbpool = adbapi.ConnectionPool('MySQLdb', **dbargs)
return cls(dbpool)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.save_city, item)
query.addErrback(self.handle_error)
return item
#插入城市的数据到tbl_all_city中
def save_city(self, conn, item):
conn.execute("""
select 1 from tbl_all_city where city_pinyin = %s
""", (item['city_pinyin'],))
ret0 = conn.fetchone()
if not ret0:
ret1 = conn.execute("""
insert into tbl_all_city(city_pinyin, city_name, home_link) values(%s, %s, %s)
""", (item['city_pinyin'], item['city_name'], item['home_link'],))
log.msg('save to tbl_all_city: %s' % ret1, level=log.INFO)
#异常处理
def handle_error(self, e):
log.err(e)
7.执行爬虫程序
scrapy crawl pm25
参考资料
1.《官方文档》
2.《在Linux CentOS 6.6上安装Python 2.7.9》