近几年团队一直在坚持在内部的 Confluence 平台上写技术文档,使用过程中发现文档的利用率较低,主要表现在如下方面:
- (1)目录层级深,找到文档入口需要花费一番功夫
- (2)搜索范围大,精细化的搜索使用成本较高
- (3)各类技术文档缺乏分类,散落在各处
为了解决这些痛点,设计了一个仅用于团队内部的技术文档管理方案。主要是实现一个数据采集器将组内的全部技术文档采集到 Elasticsearch 里面,然后利用 Elasticsearch 开箱即用的能力实现一个简易的搜索服务。整个架构如下所示:
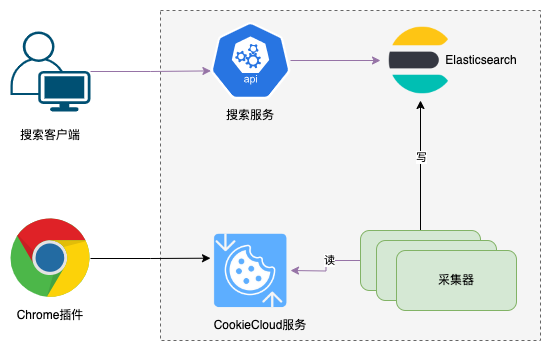
数据采集
Confluence 其实是有REST API的,其实只有一个 API:
/rest/api/content/{id}/child/page?expand={expand}&start={start}&limit={limit}
参数说明:
- id: page唯一标识符
- expand: 用于扩展返回数据字段
- start: 分页起始页码
- limit: 每页显示的条数
首先需要解决鉴权的问题,正常情况下在请求头里面添加 Authorization 字段即可,数据格式如下:
headers = {
Authorization: 'Basic ' + base64('用户名:密码')
}
但是很遗憾,这个功能被禁用了,那么只能考虑通过 Cookies 的方式了。找到了一个项目CookieCloud 。CookieCloud是一个浏览器和服务器同步Cookie的小工具,可以将浏览器的Cookie及Local storage同步到服务器上面。从官方找到一个介绍整个流程的图:
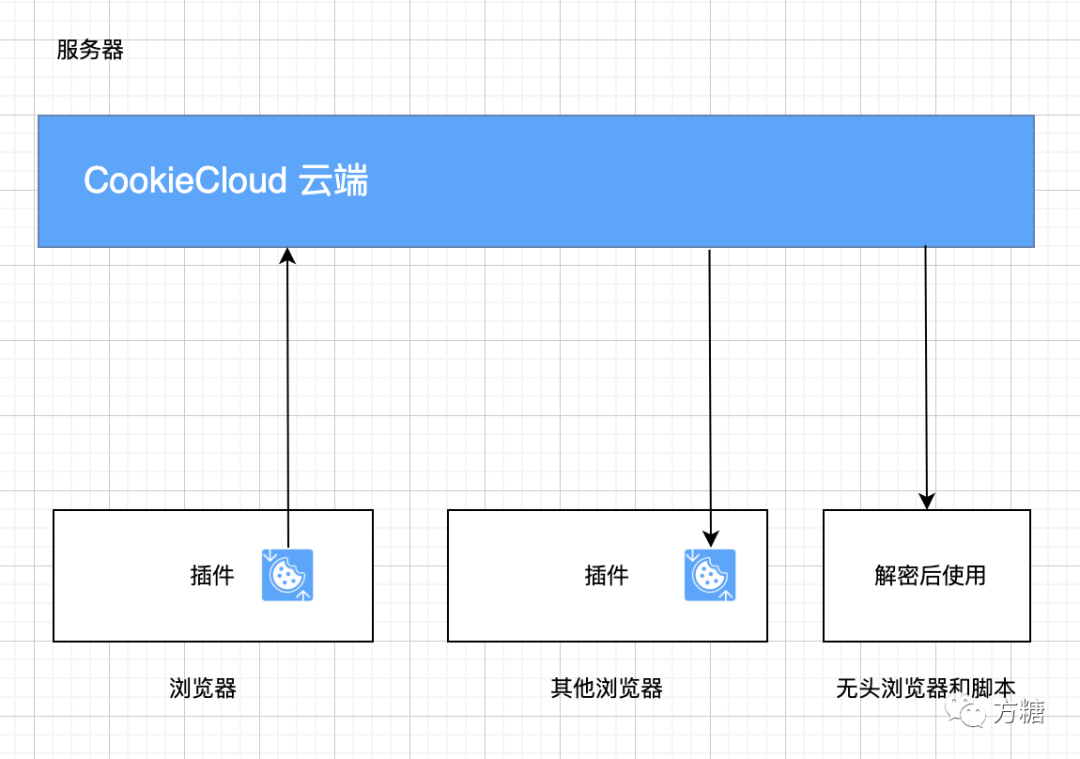
这里主要应用的场景是利用Chrome的插件将工作机器上面的Cookie同步到,采集服务部署的服务器上面,实现采集的时候自动登录。
通过 Docker 启动 cookiecloud 服务:
docker run -d -p 8088:8088 \
--restart=always \
--name cookiecloud \
easychen/cookiecloud:latest
采集器获取 Cookie 的核心代码(这里利用的是 PyCookieCloud 这个库实现):
def load_cookies(host, username, password, domains):
logger.info("load_cookies -> host: %s, username: %s, password: %s, domains: %s" % (host, username, password, domains))
cookie_cloud = PyCookieCloud(host, username, password)
decrypted_data = cookie_cloud.get_decrypted_data()
if decrypted_data is None:
logger.error("获取Cookies失败")
exit(0)
target_cookies = []
for domain in domains:
domain_data = decrypted_data[domain]
if domain_data is None or len(domain_data) <= 0:
logger.error("获取域名对应的Cookies失败: %s" % domain)
else:
target_cookies += decrypted_data[domain]
cookies = {}
for target_cookie in target_cookies:
sameSite = target_cookie['sameSite']
if sameSite != 'lax' and sameSite != 'no_restriction':
name = target_cookie['name']
value = target_cookie['value']
cookies[name] = value
return '; '.join([f"{k}={v}" for k, v in cookies.items()])
接下来就是通过递归不断的读取目录下面的文档列表,采集数据核心代码如下:
def load_child_pages(platform, base_url, index_base_url, current_page_id, cookie_str, start, limit):
expand = 'page.version,page.children.page.orderable,body.storage,history,metadata.labels,metadata.properties,space,version,ancestors'
url = "%s/rest/api/content/%s/child/page?expand=%s&start=%s&limit=%s" % (
base_url, current_page_id, expand, str(start), str(limit))
session = requests.Session()
session.cookies.set_cookie(requests.cookies.create_cookie(name='cookies', value=cookie_str))
response = session.get(url)
response_string = response.text
response_dict = json.loads(response_string)
if 'results' not in response_dict:
logger.error('请求失败: %s' % response_string)
return
# 先判断是否有数据
results = response_dict['results']
if len(results) <= 0:
return
# 解析目录数据
next_start = start
for result in results:
p_id = result['id']
title = result['title']
link = base_url + result['_links']['webui']
body = result['body']['storage']['value']
createdBy = result['history']['createdBy']['displayName']
createdDate = result['history']['createdDate']
modifyBy = result['version']['by']['displayName']
modifyDate = result['version']['when']
parent_id = result['ancestors'][-1]['id']
logger.info(" %s -> %s -> %s -> %s" % (title, parent_id, p_id, link))
page = {
'id': p_id,
'parent': parent_id,
'platform': platform,
'title': title,
'url': link,
'body': body,
'createdBy': createdBy,
'createdDate': createdDate,
'modifyBy': modifyBy,
'modifyDate': modifyDate
}
# TODO: 创建索引
# 加载子页面数据
load_child_pages(platform, base_url, index_base_url, p_id, cookie_str, start, limit)
# 尝试获取下一页的数据
next_start = next_start + limit
load_child_pages(platform, base_url, index_base_url, current_page_id, cookie_str, next_start, limit)
脚本写完了,需要在 Docker 部署,按照以往的惯例,简单编写了一个 Dockerfile :
FROM python:3.9.9
ADD . /app/
WORKDIR /app
RUN pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
CMD ["python", "main.py"]
然后编译镜像运行容器,一气呵成。但是如果需要定时运行采集的脚本,要求 工作日(周一到周五) 上午9:00到下午19:00 每隔 2 小时执行一次任务,crontab 配置:
0 9-19/2 * * MON-FRI /bin/sh entrypoint.sh >/dev/null 2>&1
Crontab 表达式生成,强烈推荐 Crontab Generator 这个网站。
其中 entrypoint.sh 的内容如下:
#!/bin/sh
export PYTHONPATH=`pwd` && python main.py
如何在容器里面实现定时任务,可以通过进入容器内部然后创建 crontab 任务即可。但是发现supercronic 这个项目可以更加方便的创建和使用。
需要在 Dockerfile 文件中添加如下代码:
ENV SUPERCRONIC_URL=https://github.com/aptible/supercronic/releases/download/v0.1.12/supercronic-linux-amd64 \
SUPERCRONIC=supercronic-linux-amd64 \
SUPERCRONIC_SHA1SUM=048b95b48b708983effb2e5c935a1ef8483d9e3e
RUN curl -fsSLO "$SUPERCRONIC_URL" \
&& echo "${SUPERCRONIC_SHA1SUM} ${SUPERCRONIC}" | sha1sum -c - \
&& chmod +x "$SUPERCRONIC" \
&& mv "$SUPERCRONIC" "/usr/local/bin/${SUPERCRONIC}" \
&& ln -s "/usr/local/bin/${SUPERCRONIC}" /usr/local/bin/supercronic \
CMD ["/usr/local/bin/supercronic", "crontab"]
最终完整的 Dockerfile 如下:
FROM python:3.9.9
COPY . /app/
WORKDIR /app
ENV SUPERCRONIC_URL=https://github.com/aptible/supercronic/releases/download/v0.1.12/supercronic-linux-amd64 \
SUPERCRONIC=supercronic-linux-amd64 \
SUPERCRONIC_SHA1SUM=048b95b48b708983effb2e5c935a1ef8483d9e3e \
PYPI_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple
RUN pip3 config set global.index-url "$PYPI_INDEX_URL" \
&& pip3 install -r requirements.txt -i "$PYPI_INDEX_URL" \
&& curl -fsSLO "$SUPERCRONIC_URL" \
&& echo "${SUPERCRONIC_SHA1SUM} ${SUPERCRONIC}" | sha1sum -c - \
&& chmod +x "$SUPERCRONIC" \
&& mv "$SUPERCRONIC" "/usr/local/bin/${SUPERCRONIC}" \
&& ln -s "/usr/local/bin/${SUPERCRONIC}" /usr/local/bin/supercronic \
CMD ["/usr/local/bin/supercronic", "crontab"]
搜索和分类
数据存储基于 Elasticsearch,通过 Docker 快速启动一个 Elasticsearch 服务(参考配置):
docker run -d \
-p 9200:9200 \
--restart=always \
--name elasticsearch \
elasticsearch:7.13.4
快速了解如何使用可以参考 全文搜索引擎 Elasticsearch 入门教程。
数据结构定义:
| 字段名 | 描述 | 备注 |
|---|---|---|
| id | 页面ID | 不为空 |
| parent | 父级页面ID | 可为空 |
| platform | 所属分类 | 不为空 |
| title | 文章标题 | 不为空 |
| url | 链接地址 | 不为空 |
| body | 内容正文 | 不为空,剔除了HTML标签 |
| createdBy | 创建人 | 可为空 |
| createdDate | 创建时间 | 可为空 |
| modifyBy | 修改人 | 可为空 |
| modifyDate | 修改时间 | 可为空 |
1、创建索引
curl -X POST 'http://localhost:9200/doc/confluence/{id}' -d '{"id":1,"parent":0,"platform":"iOS","title":"测试标题","url":"http://localhost:8080","body":"测试","createdBy":"张三","createdDate":"2023-11-05 00:23:00","modifyBy":"张三","modifyDate":"2023-11-05 00:23:00"}'
对应实现代码:
def create_index(index_base_url, data):
url = "%s/%s" % (index_base_url, data['id'])
text_body = extract_html_text(data['body']) # 剔除内容正文HTML标签
data['text'] = text_body
payload = json.dumps(data)
headers = {'Content-Type': 'application/json'}
requests.request("POST", url, headers=headers, data=payload)
2、查询
(1) 查询指定目录下面的文档
curl -X POST 'http://localhost:9200/doc/confluence/_search' -d '{"_source":{"excludes":["body","text"]},"query":{"bool":{"must":[{"match":{"parent":1}}]}},"from":0,"size":10,"sort":{"createdDate":{"order":"desc"}}}'
(2) 模糊搜索
curl -X POST 'http://localhost:9200/doc/confluence/_search' -d '{"_source":{"excludes":["body"]},"query":{"multi_match":{"query":"查询关键词","fields":["title^3","text"],"type":"most_fields","fuzziness":"AUTO"}},"highlight":{"fields":{"title":{"pre_tags":["<font style=\"color:#F00;\">"],"post_tags":["</font>"]},"text":{"pre_tags":["<font style=\"color:#F00;\">"],"post_tags":["</font>"]}}},"from":0,"size":10}'
整合
涉及到安装好几套环境,整合到一个 docker-compose.yml 配置里面,完整代码如下:
version: '2'
services:
cookiecloud:
image: easychen/cookiecloud:latest
container_name: cookiecloud-app
restart: always
volumes:
- ~/docker/doc/cookie_cloud/data:/data/api/data
ports:
- 8088:8088
elasticsearch:
image: elasticsearch:7.13.4
container_name: elasticsearch-single
restart: always
environment:
# 开启内存锁定
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
# 指定单节点启动
- discovery.type=single-node
ulimits:
# 取消内存相关限制 用于开启内存锁定
memlock:
soft: -1
hard: -1
volumes:
- ~/docker/doc/elasticsearch/data:/usr/share/elasticsearch/data
- ~/docker/doc/elasticsearch/logs:/usr/share/elasticsearch/logs
- ~/docker/doc/elasticsearch/plugins:/usr/share/elasticsearch/plugins
ports:
- 9200:9200
- 9300:9300
confluence_robot:
build: ./
container_name: confluence-robot
restart: always
environment:
- TZ=Asia/Shanghai
- INDEX_URL=http://elasticsearch_api:9200/doc/confluence
- COOKIE_URL=http://cookiecloud_api:8088
links:
- elasticsearch:elasticsearch_api
- cookiecloud:cookiecloud_api
depends_on:
- elasticsearch
- cookiecloud
volumes:
- ~/docker/doc/confluence_robot/config/config.ini:/app/config.ini
- ~/docker/doc/confluence_robot/config/crontab:/app/crontab
- ~/docker/doc/confluence_robot/logs:/app/logs
编译运行并启动:
docker-compose up --build -d
最终的效果(参考 https://faq.yunxin.163.com/kb/main/#/ 做个简单的页面):
