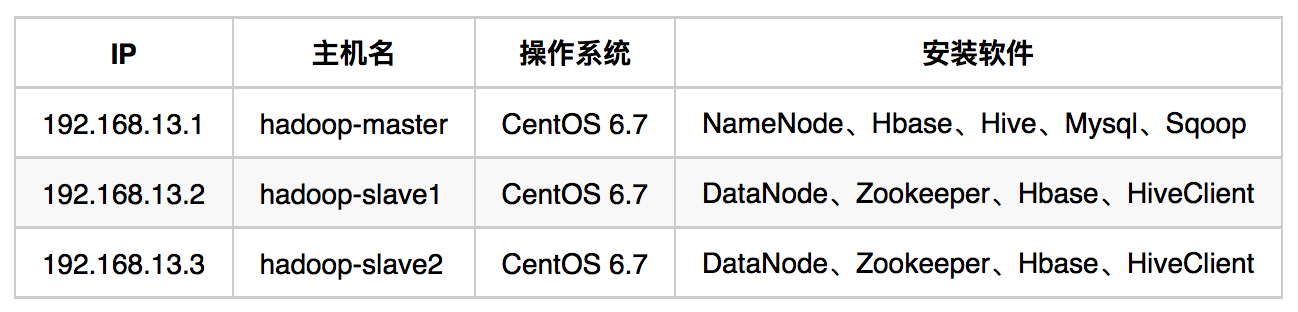
系统环境
下载软件:
- (1)JDK
- (2)Hadoop
- (3)MySQL
- (4)Hive
- (5)HBase
- (6)Zookeeper
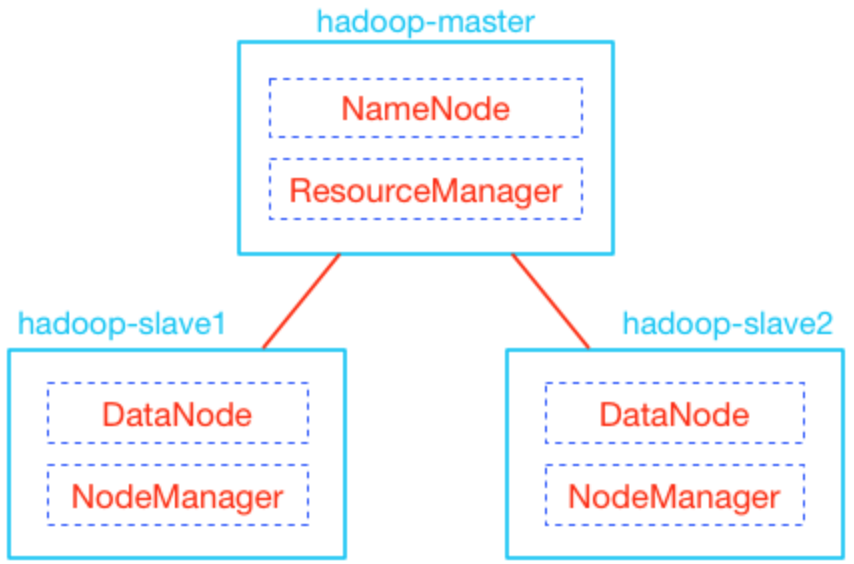
1、服务器配置
(1)修改主机名
将192.168.13.1、192.168.13.2 和 192.168.13.3 这三台机器分别命名为
hadoop-master、hadoop-slave1 和 hadoop-slave2。
1) 修改/etc/sysconfig/network文件
修改
HOSTNAME=localhost.localdomain
为
HOSTNAME=hadoop-master #这里根据情况进行调整(hadoop-master/slave1/slave2)
2)修改/etc/hosts
修改成如下代码:
127.0.0.1 hadoop-master
::1 hadoop-master
修改完成之后重启才会生效,如果想要立即生效,可以使用hostname hadoop-master的方式临时生效,下次服务器重启后就好了。
3)在每台服务器上面修改hosts文件增加如下配置:
192.168.13.1 hadoop-master
192.168.13.2 hadoop-slave1
192.168.13.3 hadoop-slave2
(2)关闭防火墙
1) 关闭selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
查看selinux状态:
/usr/sbin/sestatus -v
2) 关闭防火墙
service iptables stop
chkconfig iptables off
查看防火墙状态:
service iptables status
(3)配置SSH免密码登录
因为Hadoop需要通过SSH登录到各个节点进行操作,每台服务器都生成公钥,再合并到authorized_keys
1)开启SSH免密码登录模式
CentOS默认没有启动SSH无密码登录,需要修改/etc/ssh/sshd_config将下面的两行配置前面的注释去掉(每台服务器都要设置):
#RSAAuthentication yes
#PubkeyAuthentication yes
2)生成密钥
ssh-keygen -t rsa
执行上面的命令,一路回车即可(每台服务器都要设置)。
3)合并公钥到authorized_keys文件
cat id_rsa.pub >> authorized_keys
ssh root@192.168.13.2 cat ~/.ssh/id_rsa.pub >> authorized_keys
ssh root@192.168.13.3 cat ~/.ssh/id_rsa.pub >> authorized_keys
4)把Master服务器的authorized_keys、known_hosts复制到Slave服务器的/root/.ssh目录
scp /root/.ssh/authorized_keys root@192.168.13.2:/root/.ssh
scp /root/.ssh/known_hosts root@192.168.13.2:/root/.ssh
scp /root/.ssh/authorized_keys root@192.168.13.3:/root/.ssh
scp /root/.ssh/known_hosts root@192.168.13.3:/root/.ssh
执行完成后,使用ssh root@192.168.13.2、ssh root@192.168.13.3就不需要输入密码了
2、组件安装
(1)安装配置JDK
每台机器都需要安装JDK,所以先在hadoop-master上面安装好之后,通过scp命令拷贝到hadoop-slave1和hadoop-slave2上面。
1) 解压
mkdir -p /home/bigdata/java
tar xvf jdk-8u144-linux-x64.tar -C /home/bigdata/java
2) 配置环境变量
vi /etc/profile
#在文件末尾增加如下配置:
export JAVA_HOME=/home/bigdata/java/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存后,执行source /etc/profile使配置生效,然后可以通过java -version查看是否安装成功:
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
3)分发到各台机器上面
① 首先到各台近期上面都要创建/home/bigdata的文件目录,然后执行下面的命令:
scp -r /home/bigdata/java root@hadoop-slave1:/home/bigdata/
scp -r /home/bigdata/java root@hadoop-slave2:/home/bigdata/
② 到各台机器上面配置环境变量,和上面的配置一致
说明:
如果执行java -version不是安装的指定版本的JDK,而是系统默认的JDK的话需要先把系统的JDK卸载,可以先通过rpm -qa | grep java这个命名查出来当前安装的Java包:
java_cup-0.10k-5.el6.x86_64
pki-java-tools-9.0.3-20.el6.noarch
tzdata-java-2011l-4.el6.noarch
java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
java-1.6.0-openjdk-1.6.0.0-1.41.1.10.4.el6.x86_64
比如当前通过java -version查询出来的版本是1.6那么对应使用的包是java-1.6.0-openjdk-1.6.0.0-1.41.1.10.4.el6.x86_64,然后使用rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.41.1.10.4.el6.x86_64直接卸载就行了,反复几次直到查询Java的版本不再是系统的默认就可以了,然后使用source /etc/profile让配置生效。
(2)安装配置Zookeeper
Zookeeper安装在hadoop-slave1和hadoop-slave2上面,下面的操作都是在这两台机器上面。
1) 解压
mkdir -p /home/bigdata/zookeeper
cd /home/bigdata/zookeeper
mkdir zookeeper-data
tar zxvf zookeeper-3.4.6.tar.gz -C /home/bigdata/zookeeper
2) 配置环境变量
vi /etc/profile
#在文件末尾增加如下配置
export ZOOKEEPER_HOME=/home/bigdata/zookeeper/zookeeper-3.4.6
export PATH=$PATH:${ZOOKEEPER_HOME}/bin
保存后source /etc/profile。
3) 新建zoo.cfg配置文件
cd $ZOOKEEPER_HOME/conf
vi zoo.cfg
文件的配置内容为:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/bigdata/zookeeper/zookeeper-data
clientPort=2222
server.1=hadoop-slave1:2888:3888
server.2=hadoop-slave2:2888:3888
4) 新建myid配置文件
cd /home/bigdata/zookeeper/zookeeper-data
vi myid
这里myid里面的内容对应上面的zoo.cfg文件中server.x这个x(服务号):
如果是hadoop-slave1机器myid的内容1,hadoop-slave2机器myid的内容2。
5) 将zookeeper分发到其他机器(hadoop-slave2)
scp -r /home/bigdata/zookeeper root@hadoop-slave2:/home/bigdata
修改环境变量配置和myid的内容即可。
6)启动服务
在各台安装zookeeper的机器上面执行下面的命令启动:
cd $ZOOKEEPER_HOME/bin
zkServer.sh start #启动服务
zkServer.sh status #查看服务状态
如果需要关闭zkServer.sh stop,日志文件在当前目录下面的zookeeper.out。
(3)安装配置Hadoop
1) 解压
mkdir -p /home/bigdata/hadoop
tar xvf hadoop-2.7.4.tar -C /home/bigdata/hadoop
2) 配置Hadoop
① 创建临时文件夹
cd /home/bigdata/hadoop/hadoop-2.7.4
mkdir tmp
② 修改环境变量配置文件
vi /etc/profile
#在文件末尾追加如下配置:
export HADOOP_HOME=/home/bigdata/hadoop/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib:${HADOOP_HOME}/lib/native"
保存后source /etc/profile。
③ Hadoop基础配置
1️⃣ 设置hadoop-env.sh和yarn-env.sh中的Java环境变量
cd /home/bigdata/hadoop/hadoop-2.7.4/etc/hadoop/
vi hadoop-env.sh
#修改JAVA_HOME
export JAVA_HOME=/home/bigdata/java/jdk1.8.0_144
vi yarn-env.sh
#修改JAVA_HOME
export JAVA_HOME=/home/bigdata/java/jdk1.8.0_144
2️⃣ 配置core-site.xml配置文件
cd /home/bigdata/hadoop/hadoop-2.7.4/etc/hadoop/
vi core-site.xml
文件的配置如下:
<configuration>
<!-- 存储其他临时目录的根目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/hadoop/hadoop-2.7.4/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- 与namenode的交互端口 -->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-master:2222,hadoop-slave1:2222,hadoop-slave2:2222</value>
</property>
</configuration>
3️⃣ 配置hdfs-site.xml文件
cd /home/bigdata/hadoop/hadoop-2.7.4/etc/hadoop/
vi hdfs-site.xml
文件的配置如下:
<configuration>
<!-- 存储在本地的namenode数据镜像目录,作为namenode的冗余备份 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/bigdata/hadoop/hadoop-2.7.4/dfs/name</value>
</property>
<!-- datanode存储数据的根目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/bigdata/hadoop/hadoop-2.7.4/dfs/data</value>
</property>
<!-- 冗余数量,备份的数据量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hadoop-master</value>
</property>
<!-- namenode的http协议访问地址与端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4️⃣ 配置mapred-site.xml文件
cd /home/bigdata/hadoop/hadoop-2.7.4/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
文件的配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>hadoop-master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://hadoop-master:9001</value>
</property>
</configuration>
5️⃣ 配置yarn-site.xml文件
cd /home/bigdata/hadoop/hadoop-2.7.4/etc/hadoop/
vi yarn-site.xml
文件的配置如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-master:8088</value>
</property>
</configuration>
3) 配置集群
每台机器都需要安装Hadoop,所以先在hadoop-master上面安装好之后,通过scp命令拷贝到hadoop-slave1和hadoop-slave2上面。
1️⃣ 将hadoop安装目录分发到其他机器上面
scp -r /home/bigdata/hadoop root@hadoop-slave1:/home/bigdata/
scp -r /home/bigdata/hadoop root@hadoop-slave2:/home/bigdata/
2️⃣ 修改各自机器的/etc/profile配置文件,和上面的hadoop-master机器一样
3️⃣ 修改hadoop-master上面的slaves文件
cd /home/bigdata/hadoop/hadoop-2.7.4/etc/hadoop/
vi slaves
文件的内容如下:
hadoop-slave1
hadoop-slave2
4) 格式化文件系统
在hadoop-master机器上面执行如下命令:
hadoop namenode -format
5) 启动
在hadoop-master机器上面执行如下命令:
cd /home/bigdata/hadoop/hadoop-2.7.4/sbin
./start-dfs.sh
./start-yarn.sh
(4)安装配置Hbase
1) 解压
mkdir -p /home/bigdata/hbase
tar zxvf hbase-1.2.6-bin.tar.gz -C /home/bigdata/hbase/
2) 配置环境变量
vi /etc/profile
#在文件末尾追加如下配置
export HBASE_HOME=/home/bigdata/hbase/hbase-1.2.6
export PATH=$PATH:${HBASE_HOME}/bin
3) 配置Hbase配置文件
1️⃣ 修改hbase-env.sh文件
cd /home/bigdata/hbase/hbase-1.2.6/conf
vi hbase-env.sh
修改如下两个配置项:
export JAVA_HOME=/home/bigdata/java/jdk1.8.0_144
export HBASE_MANAGES_ZK=false
2️⃣ 修改hbase-site.xml文件
cd /home/bigdata/hbase/hbase-1.2.6/conf
vi hbase-site.xml
配置文件的内容如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-slave1,hadoop-slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/bigdata/zookeeper/zookeeper-data</value>
</property>
<property>
<name>hbase.master</name>
<value>master</value>
</property>
</configuration>
3️⃣ 修改regionservers文件
cd /home/bigdata/hbase/hbase-1.2.6/conf
vi regionservers
文件内容如下:
hadoop-slave1
hadoop-slave2
4) 同步到各台机器上面,同样修改环境变量
(5)安装配置Hive
1) 解压安装
mkdir -p /home/bigdata/hive2
tar zxvf apache-hive-2.1.1-bin.tar.gz -C /home/bigdata/hive2
2) 配置环境变量
export HIVE_HOME=/home/bigdata/hive2/apache-hive-2.1.1-bin
export PATH=$PATH:${HIVE_HOME}/bin
3) 安装配置MySQL
1️⃣ 安装MySQL
MySQL需要安装三个rpm包:MySQL-server-5.5.57-1.el6.x86_64.rpm、MySQL-client-5.5.57-1.el6.x86_64.rpm 和 MySQL-devel-5.5.57-1.el6.x86_64.rpm。
安装的命令如下:
rpm -ivh MySQL-server-5.5.57-1.el6.x86_64.rpm --force --nodeps
rpm -ivh MySQL-client-5.5.57-1.el6.x86_64.rpm --force --nodeps
rpm -ivh MySQL-devel-5.5.57-1.el6.x86_64.rpm --force --nodeps
2️⃣ 设置开机启动
chkconfig mysql on
chkconfig --list mysql
3️⃣ 设置root账号密码并配置远程连接
mysql -uroot
use mysql;
#修改密码
update user set Password = password('123456') where User='root';
#授权远程连接
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root';
#刷新权限
FLUSH PRIVILEGES;
exit;
4️⃣ 创建Hive用户
mysql -uroot -p
CREATE USER 'hive' IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'hadoop-master' WITH GRANT OPTION;
FLUSH PRIVILEGES;
5️⃣ 创建Hive表
mysql -h hadoop-master -uhive -p
CREATE DATABASE hive;
4) Hive配置
先将提前准备好的mysql jdbc的jar(mysql-connector-java-5.1.34.jar)拷贝到/home/bigdata/hive2/apache-hive-2.1.1-bin/lib这个目录下面,然后将/home/bigdata/hive2/apache-hive-2.1.1-bin/jdbc下面的hive-jdbc-2.1.1-standalone.jar文件拷贝到/home/bigdata/hive2/apache-hive-2.1.1-bin/lib下面。接下来进入到配置文件夹所在的目录进行配置:
cd /home/bigdata/hive2/apache-hive-2.1.1-bin/conf
1️⃣ 创建hive-default.xml文件
cp hive-default.xml.template hive-default.xml
2️⃣ 创建hive-site.xml文件
vi hive-site.xml
配置文件的内容为:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
</configuration>
3️⃣ 客户端配置
将hive2目录拷贝到hadoop-slave1和hadoop-slave2上面:
scp -r /home/bigdata/hive2 root@hadoop-slave1:/home/bigdata/
scp -r /home/bigdata/hive2 root@hadoop-slave2:/home/bigdata/
然后分别修改/home/bigdata/hive2/apache-hive-2.1.1-bin/conf/hive-site.xml文件的内容如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-master:9083</value>
</property>
</configuration>
5) 启动
启动metastore
hive --service metastore &
3、组件启动顺序
(1) Hadoop
在hadoop-master上面启动
cd $HADOOP_HOME/sbin
./start-all.sh
(2) zookeeper
分别到hadoop-slave1和hadoop-slave2上面执行如下代码:
cd $ZOOKEEPER_HOME/bin
./zkServer.sh start
(3) hbase
在hadoop-master上面启动
cd $HBASE_HOME/bin
./start-hbase.sh
(4) hive
在hadoop-master上面启动
hive --service metastore &
nohup $HIVE_HOME/bin/hiveserver2 &
4、组件关闭顺序
(1) Hbase
在hadoop-master上面启动
cd $HBASE_HOME/bin
./stop-hbase.sh
(2) Hive
ps -ef | grep hive
kill -9 pid
(3) Zookeeper
分别到hadoop-slave1和hadoop-slave2上面执行如下代码:
cd $ZOOKEEPER_HOME/bin
./zkServer.sh stop
(4) Hadoop
在hadoop-master上面执行:
cd $HADOOP_HOME/sbin
./stop-all.sh